
Real-Time Call Transcription with FreeSWITCH and AssemblyAI: A Debugging Journey
Recently, I dove headfirst into adding real-time audio transcription to a FreeSWITCH-based system. The idea was simple: capture the audio from a live phone call and feed it to AssemblyAI’s real-time transcription API. The reality? Not quite so simple.
Getting Started
I used Claude to help kickstart the effort. Within an hour, I had a proof of concept wired together — audio frames flowing from FreeSWITCH, over a websocket, to AssemblyAI. It looked right. The data was streaming. The AssemblyAI connection was established. I sat back, expecting a flood of beautiful transcriptions.
Nothing.
Down the Rabbit Hole
That kicked off a couple of very long days of debugging. I was convinced the issue was codec-related. FreeSWITCH was using PCMU (G.711 µ-law), which meant 8kHz audio, right? So surely I needed to tell AssemblyAI:
?encoding=pcm_mulaw&sample_rate=8000
That felt logical. It even made sense on paper. I tried it. I retried it. I tried every permutation of sample rates and encodings that AssemblyAI supported.
Still nothing.
The “Aha” Moment
Eventually, I took a step back and captured the actual audio data being sent from FreeSWITCH. When I looked at it closely, I realized something surprising: the decoded audio stream wasn’t 8kHz µ-law at all — it was already converted to 16-bit PCM at 16kHz by the time it reached my code.
Once that clicked, the fix was straightforward. I updated the AssemblyAI connection parameters to:
?encoding=pcm_s16le&sample_rate=16000
Suddenly, everything worked. Real words. Real sentences. Real-time.
A Peek at the Code
Here’s a simplified Python snippet showing how I captured audio frames in a FreeSWITCH media bug and forwarded them over a websocket to AssemblyAI:
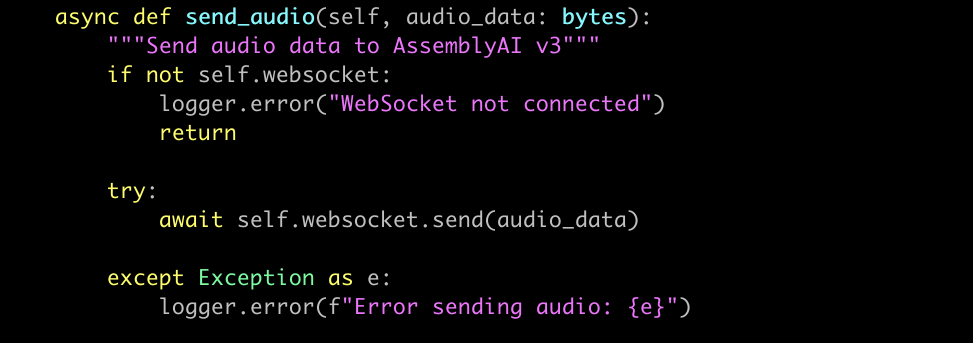
And when opening the AssemblyAI websocket connection:
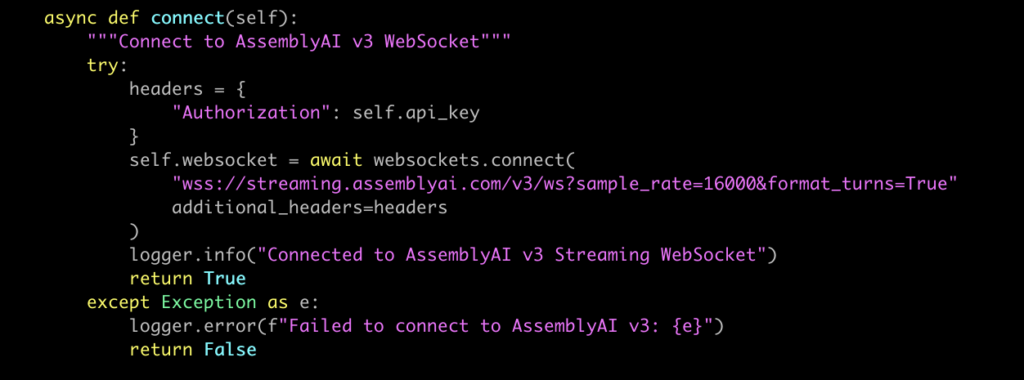
The key here: treat the audio from FreeSWITCH as raw PCM (pcm_s16le) at 16kHz, not µ-law at 8kHz.
Data Flow Overview
Here’s the high-level path the audio takes:
+-------------+ +------------------+ +---------------------+ | FreeSWITCH | -----> | Your Server | -----> | AssemblyAI Realtime | | (Media Bug) | | (via Named Pipe) | | Transcription API. | +-------------+ +------------------+ +---------------------+
Audio frames are captured inside FreeSWITCH, streamed via a named pipe on the file system into a Python Script and sent to Assembly over a websocket, and transcribed by AssemblyAI in real time.
Lessons Learned
There are a few takeaways from this little adventure:
Trust, but verify. Even if you think you know the audio format, capture and inspect it. Assumptions will lie to you.
Don’t fear the detours. It took days of wrong guesses to get to the right answer, but each failed attempt ruled out another possibility.
AI can accelerate, not replace. Claude helped me scaffold the code, but human debugging instincts were still essential.
Wrapping Up
Now I’ve got a working pipeline: FreeSWITCH → real-time websocket stream → AssemblyAI → live transcription on calls. It’s fast, accurate, and honestly, pretty satisfying to watch.
If you’re attempting something similar, save yourself the headache: use pcm_s16le and 16000. Your future self will thank you.



